背景
之前做AIO家庭服务器时,做了一个黑群晖虚拟机,把其当作家庭主要NAS使用,同时将原来古董级的DS216Play作为备份机使用。
本以为这一切就完了,慢慢使用NAS就是了,但一次偶然机会看到CMS,然后就安装了。在一个软件里面管理两台群晖NAS真的很方便。
但是,某天我发现DS216Play在休眠状态,打开DSM网址居然还能正常连接。于是我查看了两台群晖的日志文件,发现DS216Play有’Internal disks woke up from hibernation.‘的记录,而黑群晖却没有。我还特意去摸了摸两台NAS的硬盘,DS216Play凉凉的,而黑群晖居然有点烫手,打开DSM一看,硬盘温度53,而DS216Play只有30不到。
好吧,问题就来了,作为一台7x24小时运行的主机,硬盘休眠真的很重要,能节省不少能量,减少二氧化碳的排放。另外硬盘休眠了,温度自然也就降下来了,硬盘的寿命也会长一点。
群晖洗白
之前做好了黑群晖洗白,虽然只是半洗白,但完全够用,而且洗白操作应该不会影响硬盘休眠,唯一可能的关联就是网络唤醒(WOL)与硬盘休眠之间可能有一定的联系。检查一下总没什么错。
synoboot/grub.cfg
| |
修改‘sn=’/‘mac1=’/‘mac2=’后面的值 如果还未安装,可直接用DiskGenius修改synoboot.img/EFI/grub/grub.cfg
好吧,肯定会有人问这个,算号器。不要问我原始SN去哪找,这个都找不到就不要玩黑群晖了。
虚拟机设置
ESXi - 群晖虚拟机 - 编辑
网络适配器1 - E1000e - 手动 - 填写mac1对应的MAC地址
网络适配器2 - E1000e - 手动 - 填写mac2对应的MAC地址。如果不需要第二网卡,可以将‘打开电源时连接’取消掉。

验证与测试
- 查看内核启动参数
ssh登陆群晖并运行cat /proc/cmdline,检查sn/mac1/mac2

- 查看SN
群晖 - 主菜单 - 控制面板 - 信息中心 - 常规 - 硬件 - 产品序列号
- 查看MAC
ssh登陆群晖并运行ifconfig,检查MAC地址

- 登陆
群晖 - 主菜单 - 控制面板 - Synology帐户 - 登陆或注册Synology帐户。
关于QuickConnect,网上有些说法,说一定要使用群晖全球注册网站,我亲身试了一下,结果没卵用物。在中国地区使用QuickConnect就要验证手机,验证手机就要帐号转移到中国区。我还特意将synology.com/synology.cn两个域名定向到香港的服务器,一样没卵用。好吧,直接放弃,半白算了。

硬盘休眠调试
群晖 - 主菜单 - 控制面板 - 硬件与电源 - 硬盘休眠 - 启动进阶硬盘休眠
- 时间调到最小,比如10分钟,方便调试。
- 启动硬盘休眠日志
方法一
群晖 - 主菜单 - 技术支持服务 - 系统日志工具 - 启用系统休眠调试模式 - 无法休眠/经常唤醒 - 应用
| |
关注======Idle 44 seconds======这行前面的内容,逐步解决问题
通过Mon May 8 16:16:19 CST 2023定位时间区间
方法二
| |
分析问题
退出DSM并关掉网页,关掉SMB/iSCSI/http等连接,等待10-15分钟,然后开始下载分析log。这个过程可能要进行很多次,不断的分析和查找影响硬盘休眠的原因。
下载log并开始分析
| |
通过开始和结束时间定位有效log
| |
过滤已经分析过的和不需要的行
| |
通过pid查找所运行的程序、参数、用途等
| |
可疑项分析
- 由于开启了调试模式,会有很多log需要写到硬盘上,syno_hibernatio/synologrotated/syslog-ng相关的条目均可忽略。
- tmpfs相关操作都是在内存中,也不会影响我们的硬盘休眠。
- kthreadd相关内容应该是用户态程序触发的操作,直接忽略即可。
- 剩下的就是可疑条目,而且我们需要重点关注持续性或周期性输出的条目。
| |
解决问题与确认
对于找到的有问题的服务或套件,我们先可以采用停止服务或卸载套件等操作,再等待10-15分钟,再次分析,如此反复,直到所有可疑项都已经解决。
目前本人的群晖NAS就发现如下问题
- Central Management System - 本来是为了管理多个NAS方便,但得不偿失,直接卸载吧
最后,我们还要关闭所有开启的调试模式,然后再次等待10-15分钟,进日志中心,如果能够找到‘Internal disks woke up from hibernation.’相关内容,这说明硬盘已经正常休眠。如果这条内容出现得过于频繁,则说明有程序在不断的唤醒硬盘,这时需要做两方面的考虑:
- 把硬盘休眠时间设置在一个合理的值
- 对影响硬盘休眠的程序做出调整
另外,我有一点建议:我们在使用群晖的过程中,往往直接开启或关闭一个服务就Ok,但实际上控制面板中很多功能和服务都有log开关,我们在开启一个功能和服务最好连其log一并开启。
结束语
很久没有认真分析过log了,定位问题的过程还是挺有乐趣的,特别是这种中间有等待时间的问题,可以喝喝咖啡、抽抽烟,整理一下自己的思路,同时将过程完整的记录下来。这大概就是程序猿的乐趣吧!!!
另外,在定位问题的过程中,我发现黑群晖的引导文件似乎一直在处理S.M.A.R.T.相关内容,这个对cpu休眠是否有影响?下次再分析吧
| |
2023-05-20
之前调试完的的群晖,放置一夜结果仍然没有找到‘Internal disks woke up from hibernation.’,但又实在找不到其他问题,甚至关掉的所有服务都无法休眠,于是怀疑是引导文件的问题。
所以自己编译了一个群晖引导文件,然后尝试把所有日志文件写入内存(群晖的日志文件真的有点多),结果发现了新的问题。
首先,我们来看看哪些日志文件被更新了:
| |

逐个看看这些日志文件都写了什么内容
| |
从名字synofoto-bin-check-user-group来看,应该是相册引起的权限问题,那就看看

好吧,这个权限有点出乎我的意料。但这不是当前的重点,先暂时禁用‘Synology Photos’这个套件,继续分析日志问题。


目前来看就剩下‘synolog’这一项了,但这是个目录,里面文件有点多。继续查看发现,里面文件并没有改变,只是文件夹的属性更新了。这说明有程序在一直访问这个目录。
目前找不到‘synolog’的主人,线索好像断了!!!
没关系,我们再次开启硬盘休眠调试,这次我们注意到一个可疑的条目(之前被忽略了)
| |

暂时不处理,先禁用‘VMware Tools’,退出DSM,等待10-15分。
普天同庆,我们终于看到久违的‘Internal disks woke up from hibernation.’。
接下来,我们只需要处理好‘Synology Photos’和‘VMware Tools’这两个套件的问题。
Synology Photos的问题好解决,直接用chmod修改一下。
VMware Tools:
安装新版本,这是我目前能找到最新的版本了。
又是普天同庆?怎么可能那么容易。日志文件是不见了,但还是无法休眠,算了吧,暂时先卸载吧。
==> 由于ESXi+群晖是本人将来长时间采用的方案,后面我将研究一下这个Tools。
==> 在查问题过程中,发现自己MAC地址填错了,而且SN也处于失效状态,也不知道有没有影响,都修正了一下。
2023-05-21
继续昨天的任务。
虽然现在我们的硬盘已经可以休眠,但为了避免硬盘被频繁唤醒,我们仍然要将整个日志写入内存中。为了观察这点,我们特意将群晖放置一整晚,今早通过查看日志发现,果然硬盘一进休眠就被唤醒。这应该是网上所说的由于虚拟机缺少硬盘指示灯导致scemd写日志的问题。
| |
整晚都是这样,硬盘只能休眠几秒钟就被唤醒。好吧,放终极大招,将tmpfs挂载到’/var/log’,将所有日志写到内存中。
=> ‘/etc/fstab’会在开机时被‘/usr/syno/cfgen/s00_synocheckfstab’重置。如果删除或重命名这个文件,开机提示存储空间损毁。真把我吓一跳,硬盘上有不少重要东西呢。
=> 修改’/etc.default/fstab’无效。真不知道这个文件是干嘛用的。
=> 如果使用计划任务挂载tmpfs,所有套件提示损坏。大概原因是挂载’/var/log’时,已经有日志文件被打开,这时候挂载tmpfs导致之前打开的句柄无法操作。这也看得出,重定向日志文件到内存中有多重要。
=> 看来只能从syslog-ng入手了。
修改‘syslog-ng’的配置文件 – deprecated - 直接跳下一节
| |

大部分日志文件都已经定向到’/tmp/log’,还有部分模块和套件的日志没有修改。继续折腾
| |
套件的日志文件不太好修改,有些套件即写’/var/log/‘目录,也写’/var/packages/*/var/log/‘目录,只能手动修改
| |
==> 把日志定向到内存,似乎启动过程时间更长了,为什么?
==> ‘/var/log/synolog/‘这个不太好修改,很多模块都使用这个目录
添加systemd服务var-log.mount
修改‘syslog-ng’的配置文件时,突然想起来群晖也是使用systemd,既然这样就可以使用mount服务挂载‘/var/log’
| |
== update 2023-05-25 增加 var-lib-diskutil.mount
最后,恢复一下之前修改过的‘syslog-ng’配置文件
| |
真的最后了,再放置一晚,明天看结果吧。
2023-05-28
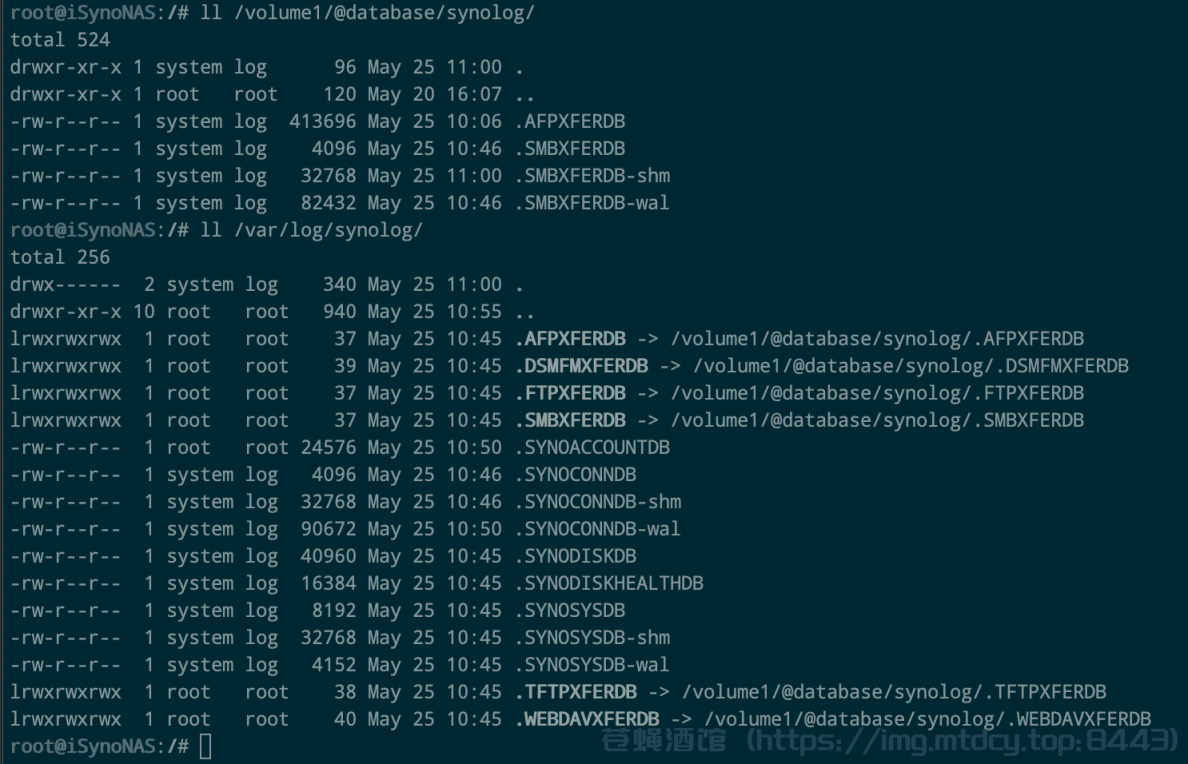
/usr/syno/plugin/volume/create/SynologVolumeCreate.sh将数据库移到/volume1然后创建链接,为什么?
VMware Tools
这个套件一直在打印一条日志:
| |
参考这里,但我们找不到vmw_vmci和vmci这两个内核模块。==> 具体错误我们暂时无法解决。
但由于我们已经实现tmpfs@/var/log/,可以把这个套件的日志文件也定向到/var/log/,不用担心唤醒硬盘。
| |
SMB Service
这个有点意外,没有数据传输的情况下,大概每小时读写一次/var/cache/samba和smbpasswd。
查看群晖官方文档发现:
文件服务: SMB/ AFP/ FTP/ NFS已启用, Synology NAS与主机之间的任何文件传输或任何 SMB/CIFS广播数据包都可能导致系统无法休眠,包括在同一网络上运行的Windows Explorer。
另外,在网上也找到一篇文章,同样是SMB的问题,人家是通过手动挂载SMB来解决的。
但是,我们怎么可能手动挂载SMB。上终极大招var-cache-samba.mount - tmpfs@/var/cache/samba。但这个操作不够解决当前问题,SMB还是需要频繁访问smbpasswd(Fuck……)。
==> Windows使用NFS,macOS使用AFP,不影响硬盘休眠。SMB还是要有的,用完就断开连接。
影响硬盘休眠的套件
- VMware Tools - 原因未确认
- WebStation - 原因未确认
- Synology Drive - 数据库读写
- Cloud Sync - 数据库读写
- SMB Service - Windows Explorer广播
- 更多可能影响硬盘休眠的套件
如非必要,可以卸载相关套件。对于必要套件,可通过任务计划 - 新增 - 计划的任务 - 服务增加两个任务来停止和启动套件:
- Stop Services Daily - 每天晚上停止相关套件
- Start Services Daily - 每天早上启动相关套件。
最佳实践
- 控制面板 - 硬件和电源 - 硬盘休眠,设定合适的休眠时间,比如30分钟;
- 设定夜间空闲时间。机器也需要休息,我设定00:00-08:00为空闲时间;
- 进入空闲时间停用非关键服务;
- 退出空闲时间启动重要服务;
- 设定某些服务为手动启动(只在进入空闲时间时停用,不在退出时启动);
- 控制面板 - 任务计划,定义好每天/每周/每月任务,并尽量避开夜间空闲时间,比如同步服务@每天0点;
- 控制面板 - 共享文件夹 - 创建回收站清空计划,避开空闲时间;
- 存储管理器 - 全局设置 - 空间回收计划,避开空闲时间;
- Hyper Backup,避开空闲时间;
- Cloud Sync - 设置 - 轮询期,设置合适的时间,比如600秒;
- Cloud Sync - 计划 - 计划设置,避开空闲时间;
- 定期重启群晖,比如@每周一07:50。这主要是因为我们使用了tmpfs,避免占用过多内存;
终于,我们的NAS可以一觉睡到天亮了。